The FCU is the core processing engine of Eva’s AI architecture, engineered to efficiently accelerate the linear algebra operations that define deep learning workloads. These systems establish General Matrix-Matrix Multiplication (GEMM)—the primary computational kernel in neural networks—as a native hardware primitive, maximizing parallelism and minimizing data movement.
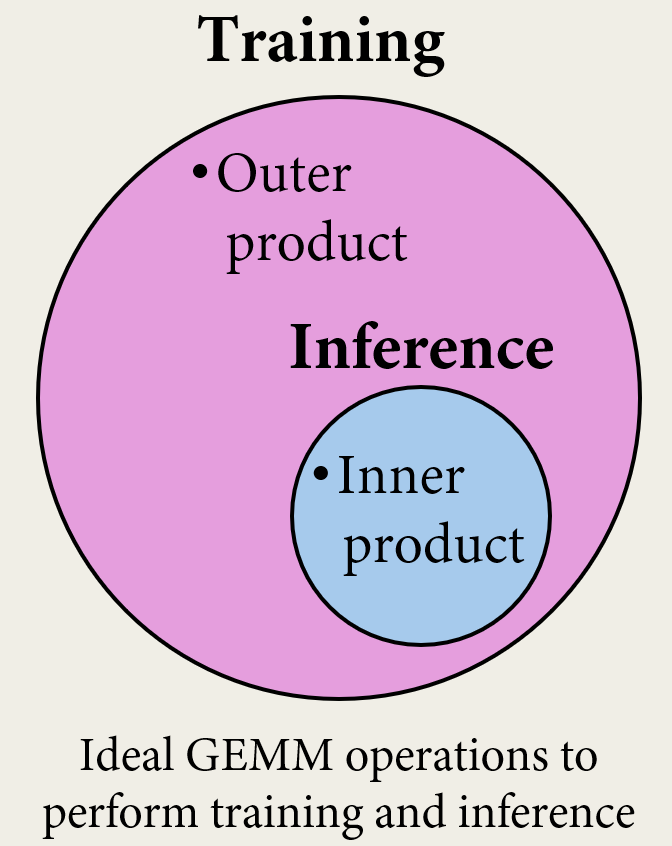
Eva’s FCU cores natively support both variants of Multiply-Accumulate (MAC) operations, enabling breakthrough performance for training and inference:
Outer Product (Training): The most effective method for gradient computation and weight updates. This formulation populates the full matrix fractionally with each iteration, allowing for the direct formation of update terms from activation-error outer products with optimal locality.
Inner Product (Training & Inference): The ideal formalism for the forward pass. By populating a fraction of the matrix fully with each iteration, this method ensures activations are efficiently accumulated along output dimensions.


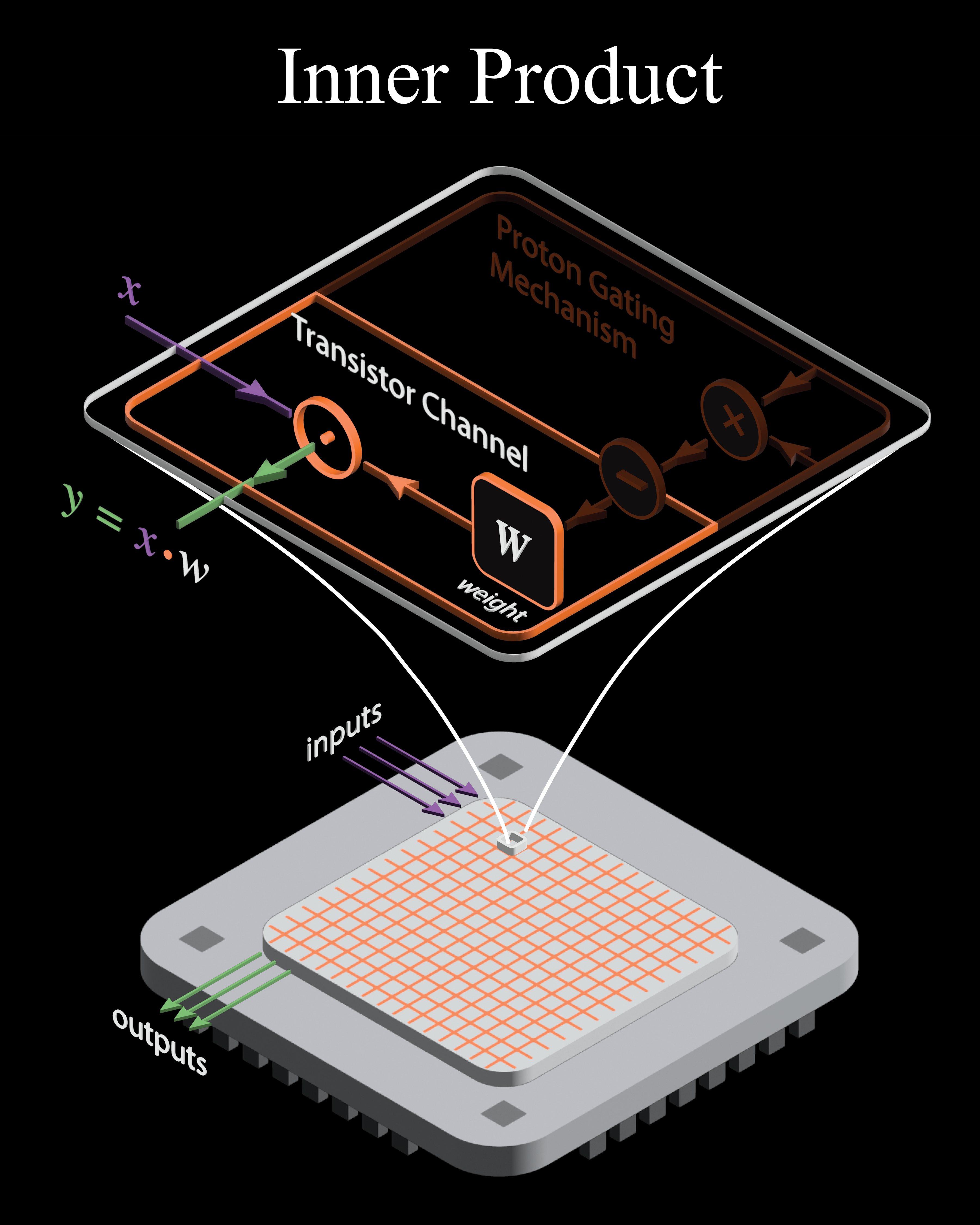
The Proton Gated Transistor (PGT) fuses memory and logic at the physical level, storing weights as device states while computing entire linear algebra primitives via intrinsic physics.
Execution of the inner product (forward/inference) is straightforward: the transistor channel multiplies inputs with weights via Ohm’s Law, while Kirchhoff’s Current Law accumulates partial sums across parallel devices in the array.
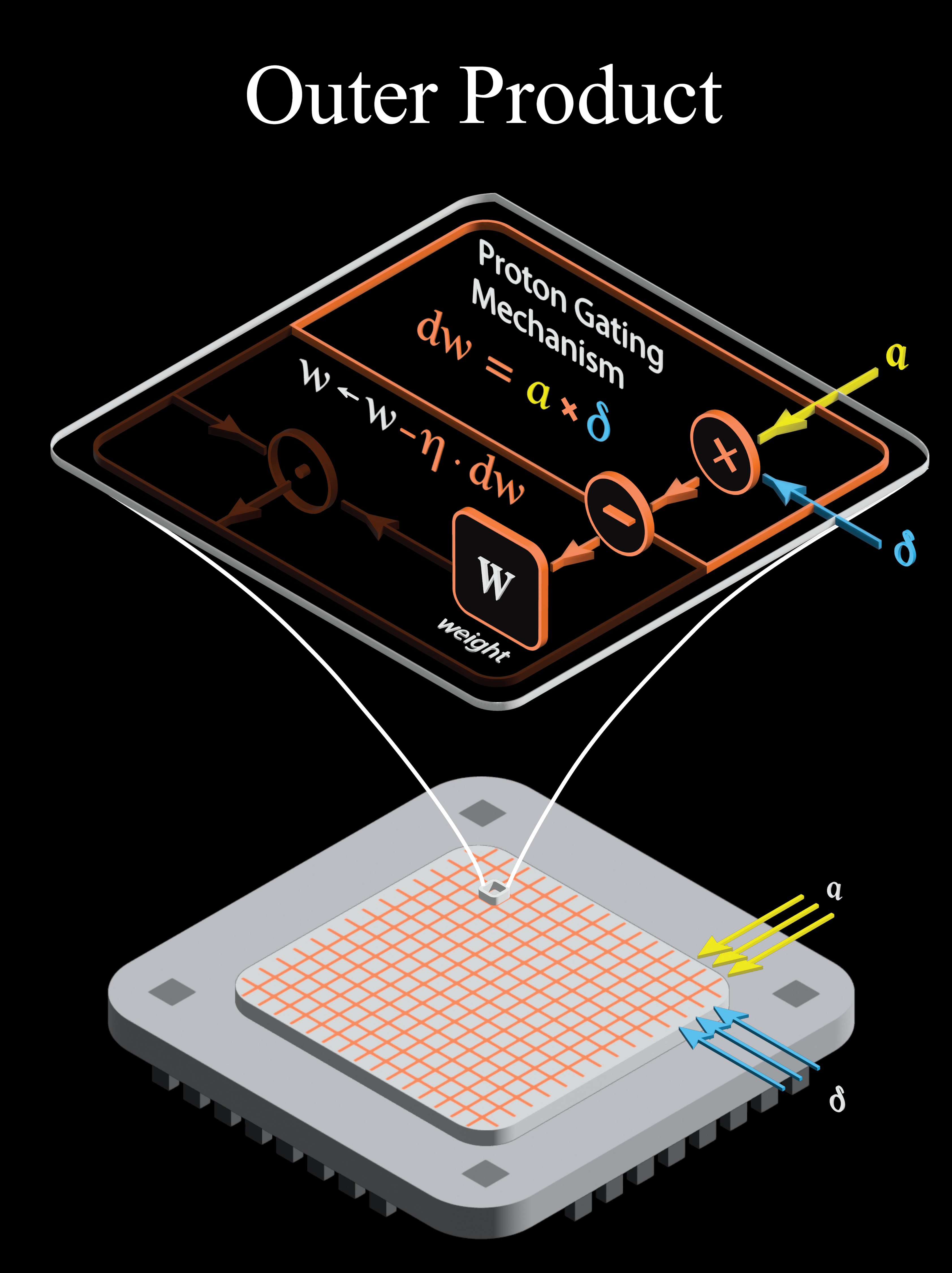
What distinguishes the PGT is its unique ability to natively support for rank-1 outer product operations (critical for computing gradients and weight updates). The proton-gating mechanism enables precise, element-wise modulation to compute the gradient update, which is applied directly and in-place to the device state, without separate memory reads/writes.
Importantly, both inner- and outer-product computations execute in a fully parallel manner across the entire FCU core. This delivers very high throughput and energy efficiency, while the local, in-device nature of these operations dramatically reduces total data movement for complex AI workloads.